Certified Kubernetes Administrator Basics
This page is basically just my notes from the KodeKloud CKA course. I primarily used their training to get my CKA.
View running service options:
1ps -aux | grep <k8s-service-name>
ETCD
ETCD is a distributed, reliable key-value store that is designed to be simple, secure, and fast.
- You cannot have duplicate keys.
- ETCD listens on port
2379by default. - The
etcdctlclient is used to interact with the key-value storage.
The kube API server is the only thing that interacts with the ETCD data store. In Kubernetes, ETCD stores nodes, pods, configs, secrets, accounts, roles, bindings, etc.
Only when a change stored in the ETCD cluster is a change considered complete.
1# How to list all keys stored by Kubernetes in the etcd-master pod
2kubectl exec etcd-master -n kube-system etcdctl get / --prefix -keys-only
3
4#If you have multiple clusters (HA cluster), then you will need to specify the different master nodes in the etcd.service file
5--initial-cluster controller-0=https://${CONTROLLER0_IP}:2380,controller-1=https://${CONTROLLER1_IP}:2380 \\
ETCDCTL version 2 supports the following commands:
1etcdctl backup
2etcdctl cluster-health
3etcdctl mk
4etcdctl mkdir
5etcdctl set
Whereas the commands are different in ETCDCTL version 3:
1etcdctl snapshot save
2etcdctl endpoint health
3etcdctl get
4etcdctl put
To set the right version of API, set the environment variable ETCDCTL_API command:
export ETCDCTL_API=3
When the API version is not set, it is assumed to be set to version 2. And the version 3 commands listed above don’t work. When the API version is set to version 3, the version 2 commands listed above don’t work.
Apart from that, you must also specify the path to certificate files so that ETCDCTL can authenticate to the ETCD API Server.
Kube API Server
The kubectl commands, after being validated, are run by the API server against the ETCD cluster and returns the data. The API server authenticates and validates requests, retrieves data, updates ETCD, and is used by the scheduler and the kubelet.
The API server passes information to the kubelet, which then updates the node. The API server is at the center of all the different tasks that need to be performed to make a change in a cluster.
1# View API server information in a deployment
2cat /etc/kubernetes/manifests/kube-apiserver.yaml
3
4# View API server service options
5cat /etc/systemd/system/kube-apiserver.service
Kube Controller Manager
Manages various controllers in Kubernetes (the brain behind various things in the cluster)
- Installed as the
kube-controller-managerpod - Continuously monitors the status of various components and works to remediate any situations to bring everything to the desired state
- Monitors the node state every
5s, and if no heartbeat is heard, there is a40sgrace period before the node is marked ‘unreachable’ - Gives the node
5 minutesbefore removing an ‘unreachable’ node and reassigning the pods to other healthy nodes - The replication controller is responsible for monitoring and ensuring that the desired number of replicas is followed
1# If a controller doesn’t work view this file:
2cat /etc/systemd/system/kube-controller-manager.service
3
4# You can see the controller manager configuration file here:
5cat /etc/kubernetes/manifests/kube-controller-manager.yaml
Kube Scheduler
The only thing this is responsible for is deciding which pod goes on which node. It doesn’t even actually place the pod on the node (that’s done by the kubelet)
The order it goes through is:
- Filters nodes to provide a best-fit for a pod
- Ranks nodes to calculate priority (0-10) based on free resources after a pod is assigned to a node
- It also considers things like resource requirements and limits, taints and tolerations, node selectors/affinity, etc.
1# View the scheduler options
2cat /etc/kubernetes/manifests/kube-scheduler.yaml
Kubelet
Responsible for doing all of the work that is required to become part of the cluster. It is the sole point of contact with the API server.
- Registers node, creates pods and monitors node/pods
Kubeadm does not automatically deploy kubelets (you must always manually install the kubelet on the worker nodes)
1# View the running kubelet process
2ps -aux | grep kubelet
Kube Proxy
Runs on every node and watches for new services, and every time a new service is created, it creates rules to forward traffic to those services to the backend pods (using iptable rules). By default, every pod can reach every other pod; this is done by a pod networking solution to the network (virtual network), which means that you want to access the pods using a service because the IP address is not guaranteed to stay the same so you want to access it via the service name.
Services cannot join the network as they aren’t actual pods (they only live in memory).
Kubeadm deploys each proxy as a pod on each node
1# View kube proxy
2kubectl get daemonset -n kube-system
ReplicaSet
Replacement for the replication controller (older tech). You can use a replicaSet even if you only have one pod as a loadbalancer across pods, and scaling is valuable.
- The replicaSet selector helps to provide info to the replicaSet about which pods fall under its control.
- The replicaSet can manage pods that weren’t created by the replicaSet (workload management).
1...
2selector:
3 matchLabels:
4 type: front-end
5...
Replace definition file:
1kubectl replace -f <file-def.yaml>
Scale replica set:
1kubectl scale —replicas=6 -f <file-def.yaml>
Alternative:
1kubetl scale —replicas=6 replicaset <rs-name>
Deployments
Deployments encapsulate replica sets. They enable modifying, scaling, updating, and rolling back pod features.
The way to create deployments is essentially the same as you would create a single pod, with a few changes.
Create an NGINX Pod:
1kubectl run nginx --image=nginx
Generate a POD manifest YAML file -o yaml and don’t actually create a pod with the --dry-run flag:
1kubectl run nginx --image=nginx --dry-run=client -o yaml
View deployments:
1kubectl get deployments
Create a deployment:
1kubectl create deployment --image=nginx nginx
Generate Deployment YAML file (-o yaml). Don’t create it(--dry-run):
1kubectl create deployment --image=nginx nginx --dry-run=client -o yaml
Generate Deployment YAML file (-o yaml). Don’t create it(–-dry-run) with 4 Replicas (--replicas=4):
1kubectl create deployment --image=nginx nginx --dry-run=client -o yaml > nginx-deployment.yaml
Save the deployment to a file, make the necessary changes to the file (for example, adding more replicas), and then create the deployment:
1kubectl create -f nginx-deployment.yaml
OR
In Kubernetes version 1.19+, we can specify the –-replicas= flag to create a deployment with 4 replicas:
1kubectl create deployment --image=nginx nginx --replicas=4 --dry-run=client -o yaml > nginx-deployment.yaml
Services
Services allow for loose coupling between pods. Services must be linked to pods via labels and selectors.
There are different kinds of services that you can use:
- Allow pods to be accessible by regular people via
nodePort - Creates a virtual IP in the cluster to allow different services to connect to each other (
clusterIP). - Loadbalancing is also a service.
Services involve three ports, and those that are not explicitly specified are left blank or assigned a default port:
- Pod port (
targetPort) - Service port (
port) - Node port (
nodePort)nodePortdefault port range: 30,000-32,767
You can group pods together for centralized connectivity between different layers of pods with clusterIP.
Load balancers can aggregate multiple node IPs from a cluster into one central IP.
- This must be supported by a cloud provider; otherwise, the loadbalancer is converted into a
nodePort.
Namespaces
The default namespace is created automatically and is called Default. Required Kubernetes services, pods, etc., are created under a different namespace called kube-system to prevent users from easily modifying Kubernetes.
kube-publicis a namespace where all resources that should be available to all users are found.
Each namespace has its own policies to define who can do what and set resource limits for each namespace. To reach a pod in the namespace, the regular pod name would work, but to reach the pod in another namespace, you need to add a suffix to the pod name, e.g., db-service.dev.svc.cluster.local
You can do this because Kubernetes creates a DNS record automatically:

View pods in other namespaces:
1kubectl get pod —namespace=<namespace-name>
Create a pod in a specific namespace:
1kubectl create -f definition.yaml —namespace=<namespace-name>
If you don’t want to specify the namespace all the time:
1# pod-definition.yaml for namespaces
2apiVersion: v1
3kind: Pod
4metadata:
5 name: myapp-pod
6 # Add the namespace here
7 namespace: dev
8 labels:
9 app: myapp
10 type: frontend
11spec:
12 containers:
13 - name: nginx-container
14 image: nginx
Create a new namespace:
1# namespace-dev.yaml
2apiVersion: v1
3kind: Namespace
4metadata:
5 name: dev
An alternative way to create a namespace (often much faster and easier):
1kubectl create namespace <namespace-name>
Switch namespaces -
1kubectl config set-context $(kubectl config current-context) —namespace=<namespace-name>
Contexts are used to manage multiple clusters.
View pods in all namespaces :
1kubectl get pods --all-namespaces
You can also set resource quotas:
1# compute-quota.yaml
2apiVersion: v1
3kind: ResourceQuota
4metadata:
5 name: compute-quota
6 namespace: dev
7
8spec:
9 hard:
10 pods: '10'
11 requests.cpu: '4'
12 requests.memory: 5Gi
13 limits.cpu: '10'
14 limits.memory: '10Gi'
Imperative vs Declarative
Imperative (IaC) - is saying what is required and how to get things done. It is often taxing as you must always know all the changes and states.
To avoid losing changes to the infrastructure, modify the YAML file and run
1kubectl replace -f FILE.yaml
2
3# to completely delete and recreate the objects add
4--force
Declarative (IaC) - is saying what is required, and the system knows what needs to be done without you needing to specify each step. For example, the kubectl apply command is intelligent enough to only create and update objects. It considers the local config file, the last applied config, and the live object definition on Kubernetes.
Create multiple objects:
1kubectl apply -f /path/to/config-files
If you simply want to test your command, use the --dry-run=client option. Generate a manifest YAML file with the -o yaml flag; this will output the resource definition in YAML format on the screen. You can use both options to create the YAML manifest files.
Create a Service named redis-service of type ClusterIP to expose pod redis on port 6379:
1kubectl expose pod redis --port=6379 --name redis-service --dry-run=client -o yaml
(This will automatically use the pod’s labels as selectors) or:
1kubectl create service clusterip redis --tcp=6379:6379 --dry-run=client -o yaml
Create a Service named nginx of type NodePort to expose pod nginx’s port 80 on port 30080 of the node:
1kubectl expose pod nginx --type=NodePort --port=80 --name=nginx-service --dry-run=client -o yaml
This will automatically use the pod’s labels as selectors, but you cannot specify the node port. You have to generate a definition file and then add the node port in manually before creating the service with the pod.
or
1kubectl create service nodeport nginx --tcp=80:80 --node-port=30080 --dry-run=client -o yaml
Scheduling
By default, every pod has a field called nodeName, which (by default) is not set as it is normally added automatically. Pods without the nodeName field are marked as candidates for scheduling, and the node that the pod is running on is added to this field. If there is no scheduler active, then that means that the pods will continue to be in a Pending state upon creation.
1# pod-definition-manual-node.yaml
2apiVersion: v1
3kind: Pod
4metadata:
5 name: nginx
6spec:
7 containers:
8 - name: nginx
9 image: nginx
10 nodeName: kube-01
Custom Schedulers
You can create your own custom scheduler. Each scheduler must have a different name, and only one scheduler can be active at a time.
1# my-custom-scheduler.yaml
2apiVersion: v1
3kind: Pod
4metadata:
5 name: my-custom-scheduler
6 namespace: kube-system
7spec:
8 containers:
9 - command:
10 - kube-scheduler
11 - --address=127.0.0.1
12 - --kubeconfig=/etc/kubernetes/scheduler.conf
13 - --config=/etc/kubernetes/my-scheduler-config.yaml
14
15 image: k8s.gcr.io/kube-scheduler-adm64:v1.11.3
16 name: kube-scheduler
1#my-scheduler-config.yaml
2apiVersion: kubescheduler.config.k8s.io/v1
3kind: KubeSchedulerConfiguration
4profiles:
5- schedulerName: my-scheduler
6# leaderElection is used when you have multiple copies of the scheduler running
7# on multiple master nodes e.g. in a HA cluster
8leaderElection:
9 leaderElect: true
10 resourceNamespace: kube-system
11 resourceName: lock-object-my-scheduler
View Schedulers:
1kubectl get pods —namespace=kube-system
1#pod-definition.yaml
2apiVersion: v1
3kind: Pod
4metadata:
5 name: nginx
6spec:
7 containers:
8 - image: nginx
9 name: nginx
10# Configure pod to use custom scheduler
11 schedulerName: my-custom-scheduler
If a scheduler is not configured correctly, then the pod will remain in a Pending state.
View events:
1kubectl get events -o wide
View scheduler logs:
1kubectl logs <my-custom-scheduler> —namespace=kube-system
Create a configMap:
1kubectl create configmap my-scheduler-config --from-file=/root/my-scheduler-config.yaml -n kube-system
This requires my-scheduler-config.yaml from above.
```yaml
apiVersion: kubescheduler.config.k8s.io/v1beta2
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: my-scheduler
leaderElection:
leaderElect: false
```
The higher the pod priority, the faster it will be deployed, as it’s more important than other pods.
Scheduling Plugins:
- Scheduling Queue (
PrioritySort) > - Filtering (
NodeResourcesFit/NodeName/NodeUnschedulable) > - Scoring (
NodeResourcesFit/ImageLocality) > - Binding (
DefaultBinder)
Extension points help us create custom plugins at each stage at any point of assigning pods to nodes.
- Scheduling Queue -
queueSort - Filtering -
filter/preFilter/postFilter - Scoring -
score/preScore/reserve - Binding -
bind/preBind/postBind/permit
Separate scheduling processes may run into race conditions (assigning pods to a node that has already run out of resources). It’s better to just add multiple schedulerName to one config file rather than keeping them all separate.
1#my-scheduler-config.yaml
2apiVersion:
3kind:
4profiles:
5- schedulerName: my-scheduler-1
6 plugins:
7 score:
8 disabled:
9 - name: TaintToleration
10 enabled:
11 - name: MyCustomPluginA
12 - name: MyCustomPluginA
13- schedulerName: my-scheduler-2
14 plugins:
15 preScore:
16 disabled:
17 - name: '*' # all prescore plugins disabled
18 score:
19 disabled:
20 - name: '*' # all score plugins disabled
21- schedulerName: my-scheduler-3
22...
Manual Scheduling
VERY IMPORTANT!!! You can only specify the nodeName at the creation time. If the pod is already created, then you will need to send a Binding command.
1# pod-bind-definition.yaml
2apiVersion: v1
3kind: Binding
4metadata:
5 name: nginx
6target:
7 apiVersion: v1
8 kind: Node
9 name: node02
Send a POST request to the pod in question with the Binding API:
1curl --header "Content-Type:application/json" --request POST --data '{"apiVersion":"v1", "kind": "Binding" ... http://$SERVER/api/v1/namespaces/default/pods/$PODNAME/binding/
Labels and Selectors
Labels are properties attached to each item.
Selectors help you filter these items.
Labels fall under the metadata section of Kubernetes (like the name). You can have an unlimited number of labels.
Get pods with a specific label:
1kubectl get pods —-selector <App=App01>
1# replicaset-definition.yaml
2apiVersion: apps/v1
3kind: ReplicaSet
4metadata:
5 name: simple-webapp
6 labels: App1
7 function: frontend
8spec:
9 replicas: 3
10 selector: .....
11
12# Labels in metadata is for the replica set
13# Labels under the template: is for the pods
14
15# To connect the replica set to the pods you will use matchLabels
16# with the label equal to the template (pod) container
Labels and selectors are used to group objects. Annotations are used like metadata on Word Docs with things like build numbers, email, etc.
Taints & Tolerations
T&Ts are used to restrict what pods can be scheduled on a node. When the master node is created, it automatically applies a taint to prevent any pods from being scheduled on it.
Taints are used to prevent certain pods from being placed on a node
- By default, all pods have no tolerations, so they wouldn’t be able to be deployed on the tainted node.
- You add tolerations to pods and taints to nodes.
Taint a node:
1kubectl taint nodes <node-name> <key=value:taint-effect>
There are three taint effects:
NoSchedule- Don’t place any new intolerant pods onto tainted nodePreferNoScheduleNoExecute- Don’t place any new intolerant pods onto the tainted node, AND evict any intolerant pods already running on the tainted node
Taints don’t guarantee that a tolerant pod will always be placed on the tainted node; taints actually tell nodes which pods to accept.
View a taint on a node:
1kubectl describe node kubemaster | grep Taint
Remove a taint from node:
1kubectl taint nodes <node-name> <taint- >
2# The - at the end is important; it's what removes the taint
1# pod-tolerations.yaml
2apiVersion: v1
3kind: Pod
4metadata:
5 name: myapp-pod
6spec:
7 containers:
8 - name: nginx-container
9 image: nginx
10 # tolerations added here
11 tolerations:
12 - key: "app"
13 value: "Equal"
14 operator: "blue"
15 effect: "NoSchedule"
Node Selectors can specify which pods go on which nodes, such as having larger and more beefy pods run on more powerful nodes.
They are configured in the spec of the definition file:
1# pod-definition.yaml
2apiVersion: v1
3...
4spec:
5 nodeSelector:
6 size: Large # size=Large is a label assigned to the node
Add label to nodes:
1kubectl label nodes <node-name> <label-key>=<label-value>
The limitation of the nodeSelector field is that you can’t specify more complex queries such as any node not this or this node and this node but not this node. 😅
Node Affinity is used (like Node Selectors) to ensure certain pods are hosted on certain nodes.
1apiVersion: apps/v1
2kind: Deployment
3metadata:
4 name: blue
5 labels:
6 app: nginx
7spec:
8 replicas: 3
9 selector:
10 matchLabels:
11 app: nginx
12 template:
13 metadata:
14 labels:
15 app: nginx
16 spec:
17 containers:
18 - name: nginx-container
19 image: nginx
20# NodeAffinity here
21 affinity:
22 nodeAffinity:
23 requiredDuringSchedulingIgnoredDuringExecution:
24 nodeSelectorTerms:
25 - matchExpressions:
26 - key: color
27 operator: In
28 values:
29 - blue
- Node Affinity Types:
1# Available currently:
2requiredDuringSchedulingIgnoredDuringExecution
3preferredDuringSchedulingIgnoredDuringExecution
4
5# Planned for future Kubernetes versions:
6requiredDuringSchedulingRequiredDuringExecution
7preferreduringSchedulingRequiredDuringExecution
Preferred means that the process on the pods is more important than putting the pod on a certain node.
You should use both taints, tolerations, and node affinity to dedicate specific nodes to specific pods. Just using taints or tolerations or node affinity by themselves will not guarantee that the pod will only go to the specific node.
Resource Limits
If no resources are available on the node, Kubernetes will avoid scheduling the pod, and it will be in a pending state. Look at events to see what is missing.
The default resources are 0.5 CPU, 256 Mi, and X Disk (requires LimitRange to be set up).
1# pod-definition.yaml
2apiVersion: v1
3kind: Pod
4metadata:
5 name: simple-webapp
6 labels:
7 name: simple-webapp
8spec:
9 containers:
10 - name: simple-webapp
11 image: simple-webapp
12 ports:
13 - containerPort: 8080
14
15# specify resources
16 resources:
17 requests:
18 memory: "1Gi"
19 cpu: 1 # (1 vCPU) .1 is lowest amount allowed
20
21# override default resource limits
22 limits:
23 memory: "2Gi"
24 cpu: 2
1# mem-limit-range.yaml
2apiVersion: v1
3kind: LimitRange
4metadata:
5 name: mem-limit-range
6spec:
7 limits:
8 - default:
9 memory: 512Mi
10 defaultRequest:
11 memory: 256Mi
12 type: Container
1# cpu-limit-range.yaml
2apiVersion: v1
3kind: LimitRange
4metadata:
5 name: cpu-limit-range
6spec:
7 limits:
8 - default:
9 cpu: 1
10 defaultRequest:
11 cpu: 0.5
12 type: Container
Default limits per container are 1 vCPU and 512 Mi memory. This needs to be set for each container, but the default values are set automatically. It’s impossible to consume more CPU than the limit, but you can consume more memory than the limit. However, if the memory limit is crossed too many times, then the pod will be terminated.
Extract the YAML configuration of a running pod to view resource limits:
1kubectl get pod webapp -o yaml > my-new-pod.yaml
Daemon Sets
Like replicasets (they help deploy multiple instances of pods), it ensures that one copy of a pod on each node is always running. Some use-cases are: monitoring solutions, logs viewers, kube-proxy (on worker nodes), networking, etc.
1# daemon-set-definition.yaml
2apiVersion: apps/v1
3kind: DaemonSet
4metadata:
5 name: monitoring-daemon
6spec:
7 selector:
8 matchLabels:
9 app: monitoring-agent
10 template:
11 metadata:
12 labels:
13 app: monitoring-agent
14
15 spec:
16 containers:
17 - name: monitoring-agent
18 image: monitoring-agent
View DaemonSet:
1kubectl get daemonsets
Get DaemonSet details:
1kubectl describe daemonsets <ds-name>
Static Pods
Static pods are helpful if you don’t have a Kubernetes master and without the API server, e.g., you only have the kubelet and docker. You need to instruct the kubelet.service to read the pod definition files from --pod-manifest-path or add a —config=….yaml file that contains staticPodPath: /path/to/manifests . This is only for pods, as others depend upon other processes.
If there is no kubectl utility, then you can view pods via docker ps.
If a kubelet creates a pod in a cluster with an API server, then the config is mirrored to the API server as read-only. Static pods are useful in creating the Kubernetes controlplane on nodes, so you don’t have to download binaries or worry about the services (just focus on their yaml files). This is how kubeadm sets up the control plane.
To find kubelet info:
1ls /var/lib/kubelet/
Logging & Monitoring
Usually, you would set up one metrics server per cluster. A metrics server is an in-memory monitoring solution, so no data is stored on the disk, which makes you unable to see historical information so you need to use the above solutions.
They often contain theKubelet, which houses the cAdvisor, which gets info from pods
Some good monitoring tools for metrics servers are things like: prometheus, elastic stack, datadog, dynatrace.
Add metrics servers - clone from a repo:
1kubectl create -f < . or monitoring-server>
View node CPU/Mem values:
1kubectl top node
View pod CPU/Mem values:
1kubectl top pod
View application pod logs:
1kubectl logs -f <pod>
View application pod running multiple containers logs:
1kubectl logs -f <pod> <container>
Application Lifecycle Management
View deployment rollout status:
1kubectl rollout status deployment/myapp-deployment
View deployment rollout history:
1kubectl rollout history deployment/myapp-deployment
Apply updates:
1kubectl apply -f …
or
1kubectl set image …
Rolling updates are good to avoid pod downtime (they are the default deployment strategy). They create an additional replicaset inside that deployment and scale the deployment down/up depending on the revision changes.
To rollback updates:
1kubectl rollout undo deployment/myapp-deployment
Commands, Arguments, Variables and Secrets
1#pod-args-definition.yaml
2apiVersion: v1
3kind: Pod
4metadata:
5 name: ubuntu-sleeper-pod
6spec:
7 containers:
8 - name: ubuntu-sleeper
9 image: ubuntu-sleeper # docker image that has sleep 5s entrypoint & CMD
10 args: ["10"] # modify CMD to sleep 10s
11 command:
12 - "sleep2.0" # modify entrypoint to something else
13 - "1000"
1#pod-env-definition.yaml
2apiVersion: v1
3kind: Pod
4metadata:
5 name: webapp
6spec:
7 containers:
8 - name: webapp-color
9 - image: webapp-color
10 ports:
11 - containterPort: 8080
12# e.g. docker run -e APP_COLOR=pink webapp-color
13 env:
14 - name: APP_COLOR
15 value: pink
It is also possible to use ConfigMap or Secrets to specify ENV variables.
1...
2# From ConfigMap
3apiVersion: v1
4kind: Pod
5metadata:
6 labels:
7 name: webapp-color
8 name: webapp-color
9 namespace: default
10spec:
11 containers:
12 - envFrom:
13 - configMapRef:
14 name: webapp-config-map
15 image: kodekloud/webapp-color
16 name: webapp-color
17
18# From Secrets
19 - envFrom:
20 - secretKeyRef:
21 name: secret-pass
ConfigMaps are centralized files that are used to pass configuration data in the form of key/value pairs.
There are 2 Phases:
- Create
ConfigMap. - Inject it into a pod.
Create a ConfigMap:
1kubectl create configmap \
2<config-name> --from-literal=APP_COLOR=blue
OR specify from a file if you have lots of key/value pairs:
1kubectl create configmap \
2<config-name> --from-file=<path/to/file>
OR :
1kubectl create -f
```yaml
# config-map.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: app-config
data:
APP_COLOR: blue
APP_MODE: prod
```
View ConfigMaps:
1kubectl get configmaps
Get ConfigMap information:
1kubectl describe configmaps
Secrets are used to store things like passwords or keys, as the values aren’t stored in plain text.
Two phases in this process:
- Create Secret.
- Inject it into a pod.
Create secret:
1kubectl create secret generic <secret-name> --from-literal=<key>=<value>
If you have multiple secrets, then you can just specify the --from-literal multiple times.
Create secret:
1kubectl create secret generic <secret-name> --from-file=<path/to/file>
1# secret-data.yaml
2apiVersion: v1
3kind: Secret
4metadata:
5 name: app-secret
6data:
7
8# THESE VALUES MUST BE PREHASHED!!!!!!
9# echo -n 'text-to-be-encoded' | base64
10 DB_Host: bserffs==
11 DB_User: Sfgs34==
12 DB_Password: SSDF3ss
View secrets:
1kubectl get secrets
Add -o yaml if you want to see the values (they are masked by default).
Get secrets info:
1kubectl describe secrets
Decode the hashed values in secret-data.yaml:
1echo -n ‘hash’ | base64 --decode
```yaml
# secrets-pod-definition.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
name: webapp-color
name: webapp-color
spec:
containers:
- name: webapp-color
image: kodekloud/webapp-color
ports:
- containerPort: 8080
# Add a secret
envFrom:
- secretRef:
name: webapp-secret
```
NOTE: Anyone with the base64 encoded secret can easily decode it. As such, the secrets can be considered not very safe. Secrets are not encrypted, so it is not safer in that sense. However, some best practices around using secrets make it safer. As in best practices like:
- Not checking in secret object definition files to source code repositories.
- Enabling Encryption at Rest for Secrets so they are stored encrypted in ETCD.
- Also, the way Kubernetes handles secrets. Such as:
- A secret is only sent to a node if a pod on that node requires it.
Kubeletstores the secret into atmpfsso that the secret is not written to disk storage.- Once the Pod that depends on the secret is deleted,
kubeletwill delete its local copy of the secret data as well. - There are other better ways of handling sensitive data, like passwords in Kubernetes, such as using tools like Helm Secrets, HashiCorp Vault.
Multi-container pods - pair logging pod and regular pod together
1# two-containers-one-pod.yaml
2apiVersion: v1
3kind: Pod
4metadata:
5 labels:
6 name: webapp-color
7 name: webapp-color
8spec:
9 containers:
10# Container 1
11 - name: webapp-color
12 image: kodekloud/webapp-color
13 ports:
14 - containerPort: 8080
15# Container 2
16 - name: webapp-color
17 image: kodekloud/webapp-color
There are three common patterns of multi-container pods: sidecar, adapter, and ambassador (only sidecar is required for CKA). Sometimes you may want to run a process that runs to completion in a container. For example, a process that pulls a code or binary from a repository that will be used by the main web application. That is a task that will be run only one time when the pod is first created.
An initContainer is configured in a pod-like all other containers, except that it is specified inside an initContainers section. When a POD is first created, the initContainer is run, and the process in the initContainer must run to completion before the real container hosting the application starts. You can configure multiple such initContainers as well, as we did for multi-pod containers. In that case, each init container is run one at a time in sequential order. If any of the initContainers fail to complete, Kubernetes restarts the Pod repeatedly until the InitContainer succeeds.
1# init-container-pod.yaml
2apiVersion: v1
3kind: Pod
4metadata:
5 name: myapp-pod
6 labels:
7 app: myapp
8spec:
9 containers:
10 - name: myapp-container
11 image: busybox:1.28
12 command: ['sh', '-c', 'echo The app is running! && sleep 3600']
13 initContainers:
14 - name: init-myservice
15 image: busybox
16 command: ['sh', '-c', 'git clone <some-repository-that-will-be-used-by-application> ;']
17 - name: init-mydb
18 image: busybox:1.28
19 command: ['sh', '-c', 'until nslookup mydb; do echo waiting for mydb; sleep 2; done;']
Cluster Maintenance
OS Upgrades
Drain workloads from one node (for maintenance):
1kubectl drain node-1
Draining a node creates pods on other nodes and terminates the existing pods. The drained node is also marked as unschedulable.
Uncordon node after drain command to enable scheduling:
1kubectl uncordon node-1
Pods will not automatically come back to this pod.
Mark a node unschedulable (cordon):
1kubectl cordon node-2
This ensures that new pods are not scheduled on the node.
NOTE: If a pod is not part of a replicaset, then you won’t be able to drain it from the node (no controller). If you force the eviction, then the pod will be lost forever!
Cluster Upgrade
Kubernetes provides support for the latest three versions. No controlplane component should ever be at a higher version than the API server.
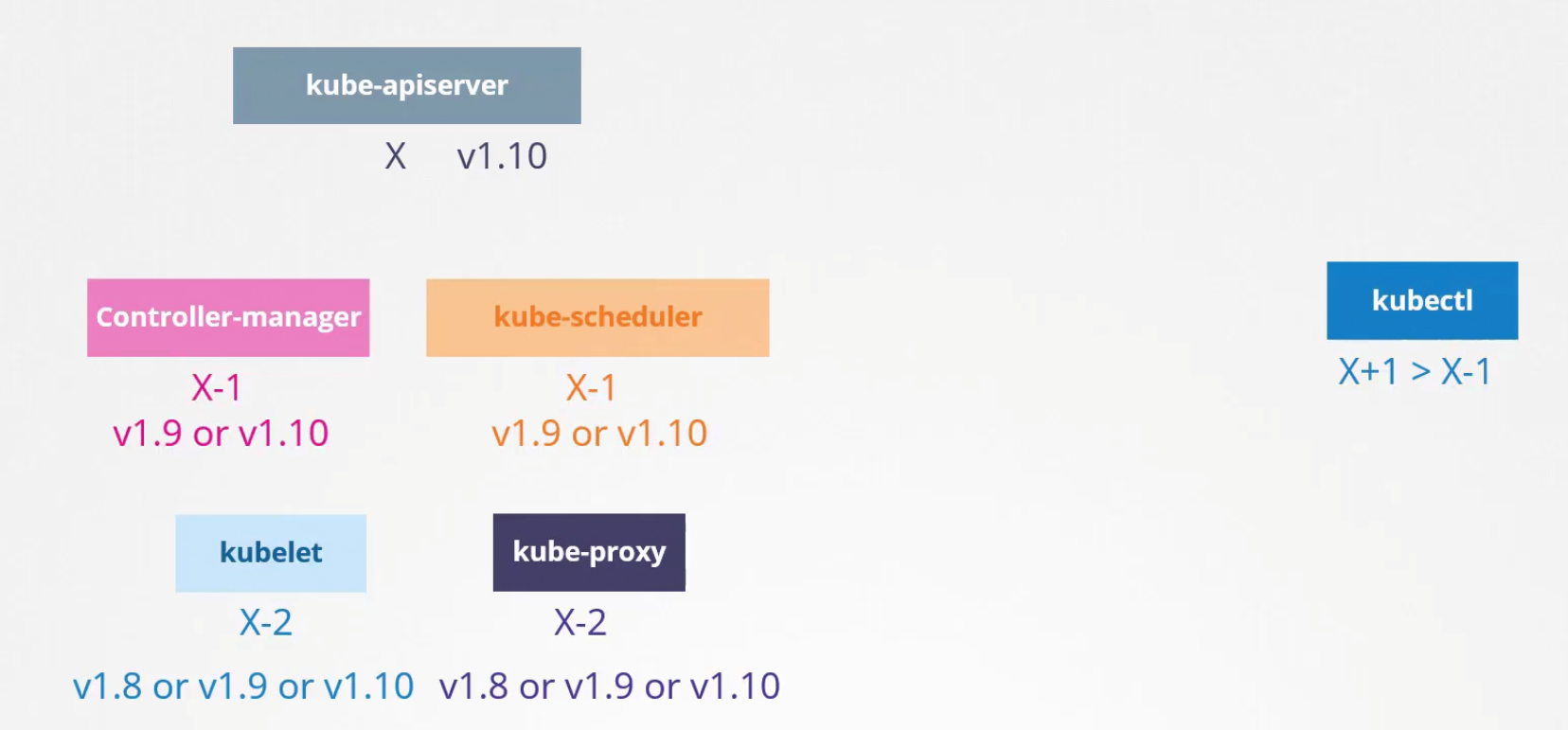
The recommended upgrade approach is to upgrade one version at a time. This upgrading process for the cluster involves two steps:
- Upgrading the master nodes.
- Then upgrading the worker nodes.
When the master is being upgraded, you can’t manage the worker nodes.
View at upgrade cluster information:
1kubeadm upgrade plan
Update kubeadm to the latest version:
1apt-get upgrade -y kubeadm=<version>
Upgrade the cluster using kubeadm:
1kubeadm upgrade apply <version>
kubectl get nodes shows the version of the kubelets and not the actual version of the cluster (master needs to run the drain node before upgrading kubelet as it’s what runs the pods).
Upgrade kubelet :
1apt-get upgrade -y kubelet=<version>
Then restart the services:
1systemctl restart kubelet
For the worker node - drain the node, apt-get upgrade kubeadm & kubelet, then…
Update the node config :
1kubeadm upgrade node config —kubelet-version <version>
Restart kubelet service, then uncordon the node
Kubernetes Backups
Good backup candidates - Resource configuration, ETCD cluster, persistent volumes. Use something like Github to store definition files.
Get all resources in YAML format:
1kubectl get all —all-namespaces -o yaml > file.yaml
Set ETCDCTL’s version to 3:
1export ETCDCTL_API=3
Take a snapshot of ETCD:
1etcdctl snapshot save /opt/snapshot-pre-boot.db \
2--endpoints=127.0.0.1:2379 \
3--cacert=/etc/kubernetes/pki/etcd/ca.crt \
4--cert=/etc/kubernetes/pki/etcd/server.crt \
5--key=/etc/kubernetes/pki/etcd/server.key
USEFUL RECOVERY MATERIAL FOR KUBERNETES CLUSTERS!!!!!
- https://github.com/etcd-io/website/blob/main/content/en/docs/v3.5/op-guide/recovery.md
- https://kubernetes.io/docs/tasks/administer-cluster/configure-upgrade-etcd/#backing-up-an-etcd-cluster
Replace save with status to view the status of the ETCD backup.
To restore the ETCD:
- Stop API server:
1service kube-apiserver stop
- Restore:
1etcdctl snapshot restore snapshot.db \ —data-dir /var/lib/<etcd-from-backup>
Configure etcd.service to use the new data-dir add - —data-dir/var/lib/etcd-from-backup to the service file.
- Reload service daemon:
1systemctl daemon-reload
- Restart ETCD service -
1service etcd restart
- Start API server -
1service kube-apiserver start
In a managed service, backups by querying the API server are best, as you may not have access to the ETCD cluster.
Security
Security primitives in Kubernetes are:
- Who can access the API server (authentication):
- Usernames, Passwords, Tokens, Certificates, LDAP, service accounts
- What can they do (authorization):
- RBAC auth
- ABAC auth
- Node auth
- Webhook mode
- Secure access to the cluster using authentication methods.
You can create/manage service accounts in Kubernetes but not user accounts:
1kubectl create/get serviceaccount <mysaaccount>
All user access is managed by the API server, which authenticates requests before processing them.
Some methods of authentication that the API server uses include Static Password Files, Static Token Files, Certificates, 3rd party authentication services (LDAP, Kerberos), etc.
Basic authentication mechanism (not secure)
-
Create a username/password CSV file
-
Add the file to the
kube-apiserver.servicefile as:--basic-auth-file=file.csv -
Restart the
apiserverprocessOR modify
/etc/kubernetes/manifests/kube-apiserver.yamland add--basic-auth-file=file.csv- The API server will automatically be restarted after any modification.
To authenticate using the username/password specified in the password CSV file:
1curl -v -k https://master-node-ip:6443/api/v1/pods -u "username:password"
You can also specify a group field in the CSV file and add a token file instead of a password with the flag: --token-auth-file=file.csv.
When authenticating, specify the token in the curl command:
1curl -v -k https://master-node-ip:6443/api/v1/pods --header "Authorization: Bearer mytoken"
TLS in Kubernetes
The Public key naming convention - *.crt, *.pem
The Private keys naming convention - *.key, *-key.pem
The keys are signed via a certificate authority for most services:
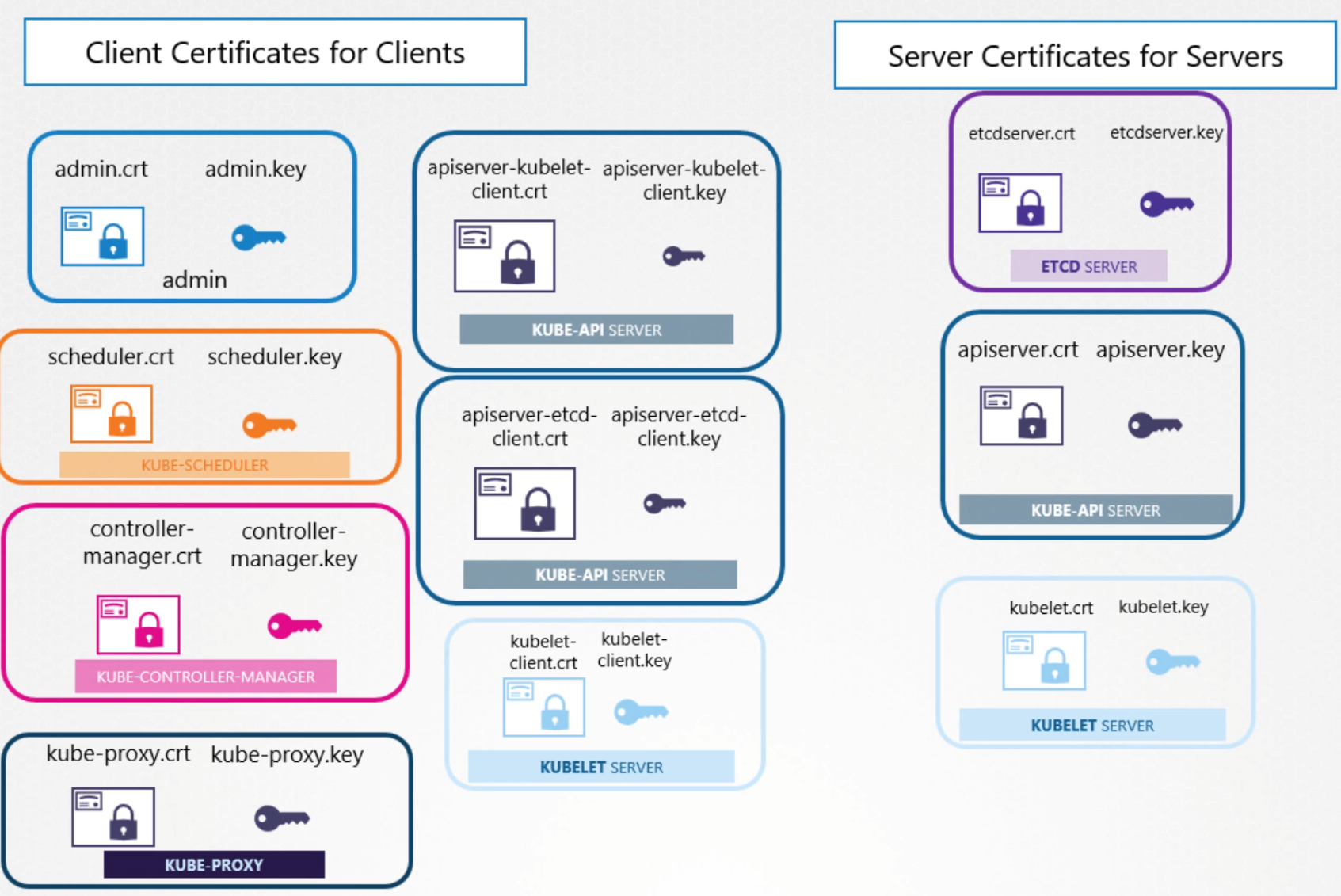
Create Client Certificates for Clients
-
Create a private key:
1openssl genrsa -out ca.key 2048 -
Create a certificate signing request:
1openssl req -new -key ca.key -subj “/CN=KUBERNETES-CA” -out ca.csr -
Sign the certificate:
1openssl x509 -req -in ca.csr -signkey ca.key -out ca.crtGoing forward, we will use this CA key pair to sign all other certificates.
-
Create an admin key:
1openssl genrsa -out admin.key 2048 -
Create a certificate signing request (CSR):
1openssl req -new -key admin.key -subj “/CN=kube-admin/O=system:masters” -out admin.csrO=is a group andsystem:mastersis the admin group in Kubernetes. -
Sign the certificate:
1openssl x509 -req -in admin.csr -CA ca.crt -CAkey ca.key -out admin.crt
Add the certificate information in the kubeconfig or specify during a CURL command.
Create Server Certificates for Servers
It is the same process as above, but we will also need to generate TLS certs to connect to peers and configure the different pods to use those peer certificates instead of using one certificate for everything.
-
Create a private key:
1openssl genrsa -out apiserver.key 2048 -
Create a certificate signing request:
1openssl req -new -key apiserver.key -subj “/CN=kube-apiserver” -out apiserver.csr -config openssl.cnf -
Specify all alternative names in an OpenSSL config file:
1#openssl.cnf 2[req] 3req_extensions = v3_req 4distinguished_name = req_distinguished_name 5[ v3_req ] 6basicConstrains = CA:FALSE 7keyUsage = nonRepudiation 8subjectAltName = @alt_names 9[alt_names] 10DNS.1 = kubernetes 11DNS.2 = kubernetes.default 12DNS.3 = kubernetes.default.svc 13DNS.4 = kubernetes.default.svc.cluster.local 14IP.1 = 10.96.0.1 15IP.2 = 172.17.0.87 -
Sign the certificate:
1openssl x509 -req -in apiserver.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out apiserver.crt -extensions v3_req -extfile openssl.cnf -days 1000
After creating the certificates now, you need to pass them into the service/executable.
-
Add the CA file :
--client-ca-file=/var/lib/kubernetes/ca.pem -
Add public server certificate:
--tls-cert-file=/var/lib/kubernetes/apiserver.crt -
Add private server certificate:
--tls-private-key-file=/var/lib/kubernetes/apiserver.key -
Do the same for
etcd:1--etcd-cafile=/var/lib/kubernetes/KEY.pem 2--etcd-certfile=/var/lib/kubernetes/KEY.crt 3--etcd-keyfile=/var/lib/kubernetes/KEY.key -
Do the same for
kubelet:1--kubelet-certificate-authority=/var/lib/kubernetes/KEY.pem 2--kubelet-client-certificate=/var/lib/kubernetes/KEY.crt 3--kubelet-client-key=/var/lib/kubernetes/KEY.key
For the kubelet to communicate with the nodes on the cluster, create certificates with the names of the nodes, and add them to the kubelet-config.yaml file for each node in the cluster. Also, for the API server to know what node is trying to communicate to it, they have to create certificates with the name system:node:node01.
- Nodes need to be added to the group
SYSTEM:NODES.
View Certificate Details
Identify all certificates that the API server uses, and look at the /etc/kubernetes/manifests/kube-apiserver.yaml file.
Decode certificate and view details:
1openssl x509 -in /etc/kubernetes/pki/apiserver.crt -text -noout
Inspect service logs:
1journalctl -u etcd.service -l
Or if their pods run:
1kubectl logs etcd-master
Or crictl ps -a to get container >ctrictl logs <container_id>.
If the API server is down, run docker ps -a > docker logs <container>.
Working the Certificate API
-
Generate a CSR file.
-
Encode the CSR in base64:
1cat my-file.csr | base64 | tr -d “\n” -
Create the CSR YAML file:
1# user-csr.yaml 2apiVersion: certificates.k8s.io/v1 3kind: CertificateSigningRequest # CSR 4metadata: 5 name: jane 6spec: 7 groups: 8 - system:authenticated 9 usages: 10 #- digital signature 11 #- key encipherment 12 #- server auth 13 - client auth 14 signerName: kubernetes.io/kube-apiserver-client 15 request: 16 <base64-enocoded-CSR-file>
View CSRs:
1kubectl get csr
- Approve CSR request:
1kubectl certificate approve <csr-name>
Get CSR:
1kubectl get csr <csr-name> -o yaml
Decode the certificate:
1echo “base64-encoded-cert” | base64 --decode
All certificate-related tasks are controlled by the Controller Manager. The controller manager file (/etc/kubernetes/manifests/kube-controller-manager.yaml) has the place where you specify the cluster signing cert/key file.
KubeConfig
By default, Kubernetes looks for the file in $HOME/.kube/config, so if it’s there, you don’t need to specify it in the kubectlcommands. The kubeconfig contains three sections: the clusters (dev, prod, etc.), the contexts (which user can access which cluster), and the users (admin, dev, guest).
By default, the kubeconfig is located in ~/.kube/config.
1#kubeconfig file
2apiVersion: v1
3kind: Config
4
5# specify what context to use by default (if multiple are in kubeconfig)
6current-context: other-user@other-cluster
7
8clusters:
9- name: my-kube-cluster
10 cluster:
11 certificate-authority: path/to/ca.crt
12
13 # optionally add certificate directly into the kubeconfig
14 certificate-authority-data: base64-encoded-certificate
15 server: https://my-kube-cluster:6443
16contexts:
17- name: my-kube-admin@my-kube-cluster
18 context:
19 cluster: my-kube-cluster
20 user: my-kube-admin
21 namespace: finance # optional if you want a specific namespace in the cluster
22users:
23- name: my-kube-admin
24 user:
25 client-certificate: path/to/admin.crt
26 client-key: path/to/admin.key
View the current kubeconfig file:
1kubectl config view
2
3# kubectl config view --kubeconfig=/root/my-kube-config
Specify a kubeconfig file:
1kubectl config view --kubeconfig=<my-custom-config>
Change the current context:
1kubectl config use-context <user>@<cluster>
API Groups
/api is where all the default tasks are located. /apis are the named groups and are more organized.
Create a kubectl proxy:
1kubectl proxy
The default port is 8001. It uses certs and credentials to access Kubernetes without needing to specify authentication.
Authorization
Authorization is done in the order that they are listed.
These are the available types:
- Node Authorizer: allows a
kubeletto perform API operations. - ABAC (attributed-based-auth): associates each user or group of users with set permissions.
- It is a JSON-formatted policy and requires the API server to restart.
- RBAC: Assign permissions to a role and assign users to the role.
- Webhook: manage auth with external tools.
- AllwaysAllow/AlwaysDeny - allows/denies all commands without checks.
- Configured in
/usr/local/bin/kube-apiserverwith--authorization-mode=RBAC,Webhook,AlwaysAllow,AllwaysDeny
- Configured in
RBAC
Roles and role bindings are namespaced, so if you don’t specify the namespace, then they go to the default namespace and control access within that namespace alone.
-
Create the RBAC object:
1# developer-role.yaml 2apiVersion: rbac.authorization.k8s.io/v1 3kind: Role 4metadata: 5 name: developer 6rules: 7# edit pods 8- apiGroups: [""] 9 resources: ["pods"] 10 verbs: ["list", "get", "create", "update", "delete"] 11 # optional: restrict access to resources 12 resourceNames: ["resource1", "resource2"] 13 14# edit deployments (new apiGroup, resources, verbs for each new type) 15- apiGroups: 16 - apps 17 resources: 18 - deployments 19 verbs: 20 - get 21 - watch 22 - create 23 - delete -
Link the user to a role:
1#devuser-developer-binding.yaml 2apiVersion: rbac.authorization.k8s.io/v1 3kind: RoleBinding 4metadata: 5 namespace: default 6 name: devuser-developer-binding 7subjects: 8- kind: User 9 name: dev-user 10 apiGroup: rbac.authorization.k8s.io 11roleRef: 12 kind: Role 13 name: developer 14 apiGroup: rbac.authorization.k8s.io
View RBAC roles:
1kubectl get roles
View role bindings:
1kubectl get rolebindings
Get more role details:
1kubectl describe role <developer>
Get more rolebinding details:
1kubectl describe rolebinding <rolebinding>
Check if you have access to do something (can I do something):
1kubectl auth can-i <command, e.g. delete nodes>
- To check access as if you’re another user, use this flag:
--as other-user
To edit existing role/rolebinding:
1kubectl edit role/rolebindings <role/rolebinding> -n <namespace>
Cluster Roles
Cluster scope is like namespaces for pods (clusterroles/clusterrolebindings).
Get namespaced resources:
1kubectl api-resources --namespaced=true/false
E.g., create a cluster admin to modify nodes or a storage admin to manage persistent volumes:
1#cluster-admin-role.yaml
2apiVersion: rbac.authorization.k8s.io/v1
3kind: ClusterRole
4metadata:
5 name: cluster-admin-role
6rules:
7- apiGroups: [""]
8 resources: ["nodes"]
9 verbs: ["list", "get", "create", "delete"]
10
11#kubectl create -f cluster-admin-role.yaml
1#cluster-admin-role-binding.yaml
2# link the cluster role to a specific user
3apiVersion: rbac.authorization.k8s.io/v1
4kind: ClusterRoleBinding
5metadata:
6 name: cluster-admin-role-binding
7subjects:
8- kind: User
9 name: cluster-admin
10 apiGroup: rbac.authorization.k8s.io
11roleRef:
12 kind: ClusterRole
13 name: cluster-admin-role
14 apiGroup: rbac.authorization.k8s.io
15
16# kubectl create -f cluster-admin-role-binding.yaml
If you authorize a user to ‘get pods’ in a cluster role, then the user will be able to get pods across the entire cluster instead of being tied to one namespace (as these roles aren’t part of any namespace).
Service Accounts
Service accounts are for machine accounts, not user accounts. When a service account is created, it also created a token automatically as a secret object; that token is what is used to authenticate (as a bearer token) an external application to Kubernetes. Each namespace has its own default service account.
You CANNOT edit the service account of an existing pod; you must delete and recreate it! However, you CAN edit the service account of a deployment.
Create a service account:
1kubectl create serviceaccount <servicename>
View service accounts:
1kubectl get serviceaccount
Get service account details:
1kubectl describe serviceaccount <servicename>
View the secret token:
1kubectl describe secret <tokenname>
You can mount the token secret as a persistent volume to simplify the external application authentication (IF the app is also on the Kubernetes cluster).
Tokens are normally stored at:
1kubectl exec -it <my-service> /var/run/secrets/kubernetes.io/serviceaccount
You can choose not to automatically mount the default service account by adding a setting within spec:
- E.g.,
automountServiceAccountToken: false
Add a custom service account to a pod by specifying the field within the pod’s spec:.
- E.g.,
serviceAccountName: <servicename>
Decode the token:
1jq -R ‘split(”.”) | select(length > 0) | .[0],.[1] | @base64d | fromjson’ <<< token
The Default token has no expiration date, so the TokenRequestAPI was created to make it more secure by making it audience, time, and object bound.
Create a token (as of v1.24 default token isn’t automatically assigned to the service account):
1kubectl create token <serviceaccount>
1#secret-definition.yaml
2# Only use this if you can't use the tokenrequest api
3apiVersion: v1
4kind: Secret
5type: kubernetes.io/service-account-token
6metadata:
7 namy: mysecretname
8 annotations:
9 # this is how you associate the secret with a particular service account
10 kubernetes.io/servce-account.name: <servicename>
To customize a service account, you need to create a role and then bind it to the service account using role binding with kind: ServiceAccount.
Image Security
To use a private registry, you need to first login so that you can pull the container.
Create a Docker credentials secret object:
1kubectl create secret docker-registry <secret-name> \
2
3--docker-server=registry.io \
4
5--docker-username=user \
6
7--docker-password=pass \
8
9--docker-email=email@email.com \
1# modify pod definition file to enable private registry images
2...
3spec:
4 containers:
5 - name: nginx
6 image: priv-registry.io/apps/internal-app
7 imagePullSecrets:
8 - name: <secret-name>
Security Contexts
Containers share the same kernel as the host. Docker has multiple users, and containers are usually run as root.
View Linux capabilities - /usr/include/linux/capability.h
1#pod-security.yaml
2apiVersion: v1
3kind: Pod
4metadata:
5 name: web-pod
6spec:
7 containers:
8 - name: ubuntu
9 image: ubuntu
10 command: ["sleep", "3600"]
11 # capabilies are only supported at the container level, not at the pod level
12 capabilities:
13 add: ["MAC_ADMIN"]
14 # this securityContext is running at the pod level, move within containers:
15 # to run at the container level
16 securityContext:
17 runAsUser: 1000
Run a command within a pod:
1kubectl exec <my-pod-name> -- whoami
Network Policies
“All Allow” is the default rule that allows traffic from any pod to any pod/service in the cluster. You can create network policies (linked to a pod) that would only allow traffic from a specific pod (labels and selectors).
1# policy is from the pods perspective (that you will attach it to)
2apiVersion: networking.k8s.io/v1
3kind: NetworkPolicy
4metadata:
5 name: db-policy
6 # optional: if the pod is in a specific namespace add it here e.g., namespace: prod
7spec:
8 podSelector: # Which pod to apply this network policy to
9 matchLabels:
10 role: db
11 policyTypes: # Pod can still make any egress calls (not blocked)
12 - Ingress
13 ingress:
14 - from: # egress traffic would be - to: (traffic from pod to external server)
15 # you can have multiple to/from if you use different ports
16 - podSelector:
17 matchLabels:
18 name: api-pod
19 # optional: add a namespace selector
20 namespaceSelector:
21 matchLabels:
22 name: prod
23 # optional: add an Ip block (for servers outside of the cluster)
24 - ipBlock:
25 cidr: 192.168.5.10/32
26 ports:
27 - protocol: TCP
28 port: 3306
Adding both Ingress and Egress policyTypes will block all traffic in a pod (no need to specify ports or anything else). Network policies are stateful, so there is no need for explicit allows; you are only concerned with the direction in that the request originates, so there’s mo need to worry about the response.
Kubectx & Kubens
Kubectx:
With this tool, you don’t have to use lengthy “kubectl config” commands to switch between contexts. This tool is particularly useful for switching contexts between clusters in a multi-cluster environment.
Installation:
1sudo git clone https://github.com/ahmetb/kubectx /opt/kubectxsudo ln -s /opt/kubectx/kubectx /usr/local/bin/kubectx
Syntax:
To list all contexts - `kubectx`
To switch to a new context - `kubectx`
To switch back to the previous context - `kubectx –`
To see the current context - `kubectx -c`
Kubens:
This tool allows users to switch between namespaces quickly with a simple command.
Installation:
1sudo git clone https://github.com/ahmetb/kubectx /opt/kubectxsudo ln -s /opt/kubectx/kubens /usr/local/bin/kubens
Syntax:
To switch to a new namespace - `kubens`
To switch back to the previous namespace - `kubens –`
Storage
Docker Storage
All docker storage is under /var/lib/docker by default. This is good because Docker containers are made in a layered structure so it can reuse the same layer from the cache (which saves time during builds and updates).
You can create a persistent volume and then mount it to the Docker container upon creation to save files to your host if the container fails (AKA volume mounting).
1docker run \
2 --mount type=bind/mount, \
3 source=<host_volume>, \
4 target=<path/to/mount/inside/the/container_volume>, \
5 container
Add the full host_volume path if the folder is outside of /var/lib/docker (AKA bind mounting).
Storage drivers are used to manage the volumes; they change depending on the underlying OS (chosen by Docker automatically)
- Storage drivers: AUFS, ZFS, BTRFS, Device Mapper, Overlay, Overlay2
- Volume drivers: Local, Azure FS, Convoy, Flocker, GlusterFS, VMware vSphere, Rexray
- E.g.
docker run ... --volume-driver rexray/ebs
- E.g.
Kubernetes Storage
A long time ago, Kubernetes was only with Docker, so all Docker code will work with Kubernetes. Once more container software was created, they had to create a Container Runtime Interface. The CRI says how orchestration tools should interact with different container runtimes.
The Container Network Interface (CNI) was also created to work with different networking solutions.
The Container Storage Interface (CSI) was also created for Kubernetes to interact with multiple storage solutions. The CSI is not a Kubernetes standard but is meant to be a universal standard to work with any storage vendor.

1#volume-and-mount.yaml
2apiVersion: v1
3kind: Pod
4metadata:
5 name: random-num-generator
6spec:
7 containers:
8 - image: alpine
9 name: alpine
10 command: ["/bin/sh", "-c"]
11 args: ["shuf -e 0-100 -n 1 >> /opt/number.out;"]
12 # mount the volume to the container
13 volumeMounts:
14 - mountPath: /opt
15 name: data-volume
16
17 # define the volume
18 volumes:
19 - name: data-volume
20 hostPath: # store data on the /data dir on the node (host)
21 path: /data
22 type: Directory
23
24# Example on how to configure pod to use AWS block storage across a multi-node
25# environment
26 volumes:
27 - name: data-volume
28 awsElasticBlockStore:
29 volumeID: <volume-id>
30 fsType: ext4
Persistent volumes are better than volumes as storage management can be centralized. You can assign a storage pool for persistent volumes that pods can automatically pull from. They are cluster-wide and pods can take from the pool by using Persistent Volume Claims (PVC) and are two different things.
1#persistant-volume-def.yaml
2apiVersion: v1
3kind: PersistentVolume
4metadata:
5 name: pv-vol01
6spec:
7 accessModes:
8 - ReadWriteOnce
9 capacity:
10 storage: 1Gi
11 hostPath: # hostPath shouldn't be used in prod (use a storage solution like AWS)
12 path: /tmp/data
13
14# kubectl create -f persistent-volume-def.yaml
Get the persistent volume(s):
1kubectl get persistentvolume
PVCs are used to try to find the most fitting PV; if there are multiple PVs that you like, then you can use labels & selectors to bind to a PV. There is a 1:1 relationship between claims and volumes, so no other claims can utilize the remaining capacity in the volume. If no volumes are available, then they will remain in a Pending state and automatically resume once more storage was added.
1#pvc-def.yaml
2apiVersion: v1
3kind: PersistentVolumeClaim
4metadata:
5 name: myclaim
6spec:
7 # for storage classes, you would need to add storageClassName here
8 storageClassName: google-storage
9
10 accessModes:
11 - ReadWriteOnce
12 resources:
13 requests:
14 storage: 500Mi
15
16# kubectl create -f pvc-def.yaml
View created claims:
1kubectl get persistentvolumeclaim
Delete a PVC:
1kubectl delete persistentvolumeclaim <myclaim>
If you delete a PVC, then by default, the data on the volume is Retained. Other options are Delete and Recycle (scrub data off the PV & reallocate). Once you create a PVC, use it in a POD definition file by specifying the PVC Claim name under persistentVolumeClaim section in the volumes section like this:
1#pod-pvc-def.yaml
2apiVersion: v1
3kind: Pod
4metadata:
5 name: mypod
6spec:
7 containers:
8 - name: myfrontend
9 image: nginx
10 volumeMounts:
11 - mountPath: "/var/www/html"
12 name: mypd
13 volumes:
14 - name: mypd
15 persistentVolumeClaim:
16 claimName: myclaim
The same is true for ReplicaSets or Deployments. Add this to the pod template section of a Deployment on ReplicaSet.
To use PV by default, you need to create a disk manually 😢 (static provisioning). You can create a storage class that will automatically provision storage and attaches them to pods (dynamic provisioning).
If you use a storage class, then you DON’T need a PV definition file!
1#sc-def.yaml
2apiVersion: storage.k8s.io/v1
3kind: StorageClass
4metadata:
5 name: google-storage
6# there are many volume plugin provisioners
7provisioner: kubernetes.io/gce-pd
8# optional:
9parameters:
10 type: pd-standard/pd-ssd # type of disk
11 replication-type: none/regional-pd
You then add the storage class name to the PVC for it to know what storage class to use.
Networking
Most of this networking information is unnecessary for the CKA exam.
Prerequisites
Add IP to network interface:
1ip addr add IP/CIDR dev INTERFACE
This doesn’t persist. You need to modify the network interfaces file.
Show kernel routing table:
1route
Configure path to another network:
1ip route add OTHER-NETWORK/CIDR via GATEWAY
Create a default (0.0.0.0) route:
1ip route add default via GATEWAY
On Linux, by default, packets are not forwarded from one interface to another.
View if packet forwarding is enabled:
1cat /proc/sys/net/ipv4/ip_forward
Modify /etc/sysctl.conf to persist these settings (net.ipv4.ip_forward).
List and modify interfaces on the host:
1ip link
Execute command inside a specific namespace:
1ip -n <namespace> link
Add a DNS server - /etc/resolv.conf
- Append a domain name -
search DOMAIN.com
Modify the DNS lookup order - /etc/nsswitch.conf
Create Linux namespaces:
1ip netns add <namespace>
View namespaces:
1ip netns
Delete an IP link in a namespace:
1ip -n <red> link del <veth-red>
Here is the hard way to configure networking between namespaces:
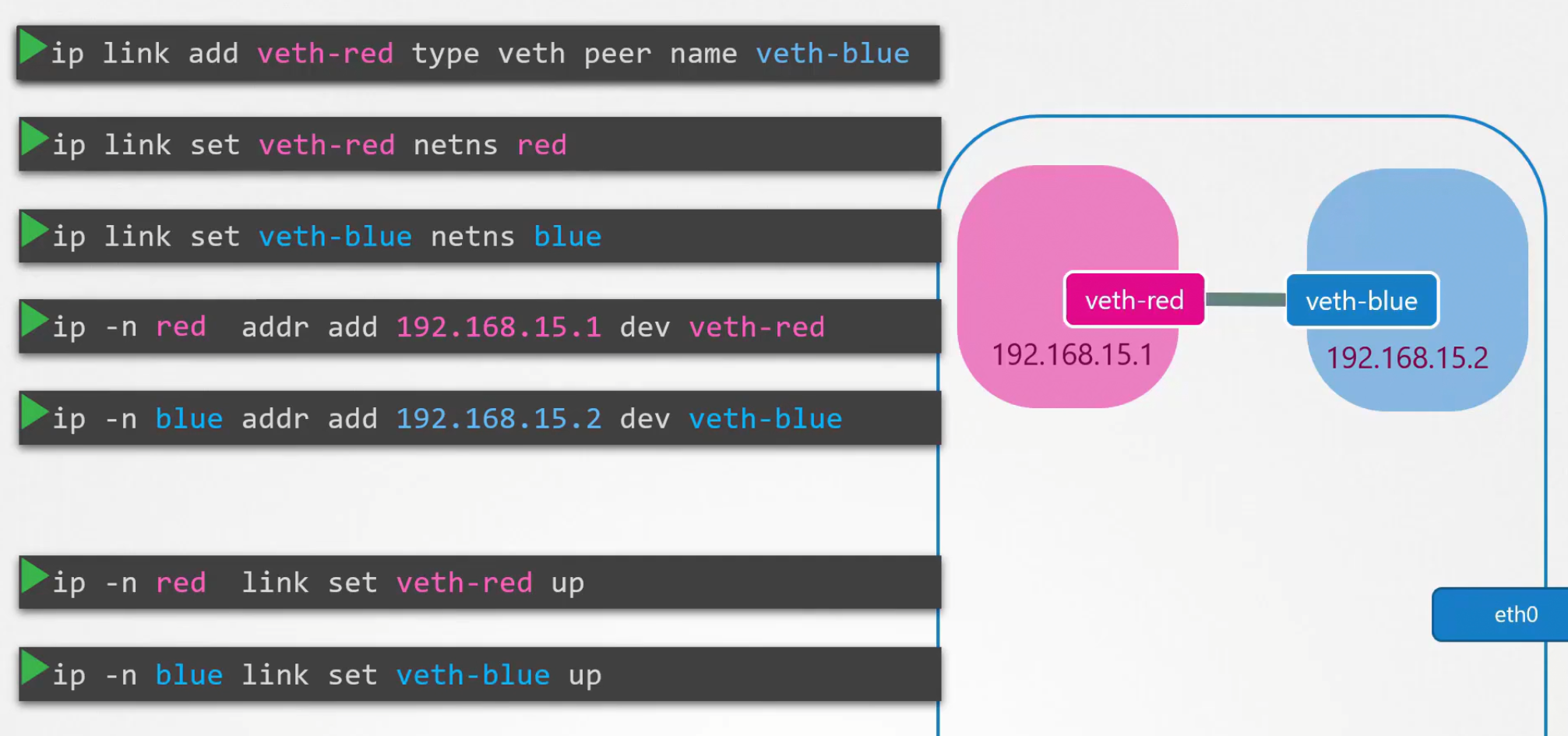
This is the easy way to configure networking between namespaces:
-
Create a virtual switch:
1ip link add v-net-0 type bridge -
Create links between the namespace and the virtual switch:
1ip link add veth-red type veth peer name veth-red-br 2 3ip link add veth-blue type veth peer name veth-blue-br -
Connect the virtual interfaces to the namespace:
1ip link set veth-red netns red 2ip link set veth-red-br master v-net-0 3 4ip link set veth-blue netns blue 5ip link set veth-blue-br master v-net-0 -
Assign IPs to the interfaces and bring them up:
1ip -n red addr add 192.168.15.1 dev veth-red 2ip -n red link set veth-red up 3 4ip -n blue addr add 192.168.15.2 dev veth-blue 5ip -n blue link set veth-blue upYou can attach an IP to
v-net-0interface on the localhost and then use it as the default gateway to other networks + enable IP forwarding.
Use iptables to enable NAT so that traffic from inside the namespace appears to be coming from the host instead:
1iptables -t nat -A POSTROUTING -s 192.168.15.0/24 -j MASQUERADE
You can add a port forwarding rule for outside traffic to communicate to the inside of the namespace:
1iptables -t nat -A PREROUTING --dport 80 --to-destination 192.168.15.2:80 -j DNAT
Docker has different network configs - none (nothing can access the container), host (no separation between container network and host network), and bridged (a private network).
View namespace:
1ip netns
View your end of the link:
1ip link
View the container end of the link:
1ip -n <ip netns output> link
View the container IP link:
1ip -n <ip netns output> addr
Odd & even interfaces form a pair. Docker does the same thing as Linux (just uses different commands/names):
- Create Network Namespace
- Create Bridge Network/Interface
- Create Veth Pairs (Pipe, Virtual Cable)
- Attach Veth to Namespace
- Attach other Veth to bridge
- Assign IP addresses
- Bring the interfaces up
- Enable NAT - IP Masquerade
To provide access to a container outside of the host, you need to use port mapping (if bridged). Simply map port -p 8080:80 in Docker (mapping is done using iptablesrules).
Since all of the steps above are pretty much the same for all of the different container orchestration tools, they simply script it out.
Add a bridge:
1bridge add <container-id> <namespace>
Container network interface (CNI) is a set of standards that define how programs should be developed to solve networking challenges in a container runtime environment (aka. plugins):


CNI already has supported plugins - bridge, VLAN, ipvlan, macvlan, windows, DHCP, host-local + plugins from 3rd parties.
- Docker doesn’t implement CNI but uses its own model (CNM) and will have to manually invoke plugins.
Networking Cluster Nodes
Each node interface must be connected to a network with a unique IP address, unique hostname, and unique MAC address.
Then you need to open up some ports:
- The master node should allow port
6443for the API server to control worker nodes.10250to allow kubelet.10251to allow kube-scheduler.10252to allow kube-controller-manager.2379to allow etcd server.
- If you have multiple master nodes, then you also need to have port
2380open to allow the etcd clients to communicate between master nodes. - Worker nodes should allow port
10250for the kubelet.- They also expose ports
30000-32767for external services.
- They also expose ports
2379 is the port of ETCD to which all control plane components connect to. 2380 is only for etcd peer-to-peer connectivity. 2380 is for when you have multiple controlplane nodes.
Pod Networking
Kubernetes doesn’t come with a networking solution; it expects you to implement your own to solve this challenge.

- Assign an IP address to each node
- Add pods to a bridged virtual network
- Bring the virtual network up
- Assign an IP address to each virtual network (node side)
- Connect pods to the network and allow communication between pods on the same node
- Add a route to allow another node to communicate with the pod on another node (on a router and point nodes to use the router)
The CNI plugin is configured on the kublet service on each node. The kublet looks into (ps -aux | grep kubelet to see where):
--cni-conf-dir=...- contains configuration files to see what plugin to use (multiple files in this dir will mean choosing the file by alphabetical order)--cni-bin-dir=...- contains all the supported plugins (default is/opt/cni/bin)- Also
--network-plugin=cni
CNI Example using Weavework
A Weaveworks agent is deployed on each node to handle networking (all agents store the entire topology of the entire network). When a pod sends a packet to another node, weave intercepts the packet and encapsulates it with a new source and destination, then sends it across the network, and once on the other side, the other weave agent decapsulates the packet and forwards it to the right place.
Find what route a pod will use:
1kubectl exec <pod> ip route
Deploy weave as a daemonset:
1kubectl apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -f '\m')"
A daemonset ensures that one pod of each kind is deployed on all nodes in the cluster.
You can view the weave peers by simply running:
1kubectl get pods
For troubleshooting weave:
1kubectl logs <weave-pod> weave -n kube-system
The IP Address Management (IPAM) CNI assigns IPs to containers via DHCP and host-local plugin. It can be found under the directory: /etc/cni/net.d/.
Service Networking
When a service is created, it is accessible from all pods on the cluster (ClusterIP), irrespective of what nodes the pods are on.
kube-proxy gets a predefined range of IP addresses and assigns the IPs to services, then creates forwarding rules on the cluster that says that any traffic that goes to the IP/port of the service should go to the IP/port of the pod.
- This IP range is specified in
kube-api-server --service-cluster-ip-range ###(Default:10.0.0.0/24) - useps auxto find it easy kube-proxycreates these rules using either:iptables,userspaceoripvs
The pod network range and service network range should never overlap!
Set proxy mode when configuring the kube-proxy service:
1kube-proxy --proxy-mode [userspace | iptables | ipvs]...
If you use iptables then use to see DNAT rules:
1iptables -L -t nat | grep <service>
You can see kube-proxy create these service entries in - /var/log/kube-proxy.log (this path changes).
DNS in Kubernetes
By default, Kubernetes has a DNS server for name resolution for pods/services. Whenever a service is created, the Kubernetes DNS server creates a record of that service (service name mapped & IP mapping).
The Kubernetes DNS server also creates a subdomain for the namespace of the service.
-
Then they are grouped into their type (
svc). -
Finally, they are grouped into a root domain (
cluster.local). -
E.g., the FQDN would be:
1curl http://<service-name>.<namespace>.<svc>.<cluster.local>(leave blank if the service is in the default namespace)
For pods, the name is changed from the pod name to the IP address by replacing the dots with dashes, e.g., 10.244.2.3 → 10-244-2-3. The type is also set to pod instead of svc.
CoreDNS in Kubernetes
DNS is deployed as two pods in a replicasetin a deployment in the kube-system namespace.
The Corefile is located at /etc/coredns/Corefile, which is passed into coredns pod via configmap.
1// Example of the Corefile
2.:53{
3 errors
4 health
5 kubernetes cluster.local in-addr.arpa ip6.arpa {
6 pods insecure
7 upstream
8 fallthrough in-addr.arpa ip6.arpa
9 }
10 prometheus :9153
11 proxy . /etc/resove.conf
12 cache 30
13 reload
14}
15// This is a configmap so you can modify it later
16// E.g. kubectl get configmap -n kube-system
When the CoreDNS pod is created, it also creates a service called kube-dns with an IP. That service IP is put into each pod’s/etc/recov.conf file so that they can resolve domain names (the kubelet is responsible for configuring all this ). resolve.conf contains a search field so that you can use host or nslookup to find the service
To find a pod, you would need to specify the FQDN.
Services (Ingress)
If you are hosting an app on-prem - Service NodePorts can only allocate high port ranges (>30,000), but in a production environment, you don’t want users to remember the high port number - just 80 or 443, so you can use a proxy server that proxies requests on port 80 to port, e.g., 38,080 on the nodes. Defining the IP of the proxy server on your domain name make it easy for users to access your app on port 80.
In a cloud, you can usually create a LoadBalancer service that does everything on-prem but talks to the cloud provider automatically to provision a loadbalancer for this service to route traffic to all the nodes.
Ingress helps your users access your app using a single external URL that you can configure to route to different services based on the URL path and can also implement SSL security. It is like a L7 loadbalancer that is built into Kubernetes.
But even with ingress, you still need to expose it to have it accessible outside the cluster, so you would need to public it as a NodePort or a LoadBalancer, but this only needs to be set up once.
The ingress tools that you deploy (nginx, haproxy, traefik) are called ingress controllers.
The ingress rules are called ingress resources - and are created using definition files.
- Kubernetes clusters don’t come with an ingress controller by default.
You must create the ingress deployment, ingress service, ingress configmap, and ingress service account.
1---
2apiVersion: apps/v1
3kind: Deployment
4metadata:
5 name: ingress-controller
6 namespace: ingress-space
7spec:
8 replicas: 1
9 selector:
10 matchLabels:
11 name: nginx-ingress
12 template:
13 metadata:
14 labels:
15 name: nginx-ingress
16 spec:
17 serviceAccountName: ingress-serviceaccount
18 containers:
19 - name: nginx-ingress-controller
20 image: quay.io/kubernetes-ingress-controller/nginx-ingress-controller:0.21.0
21 args:
22 - /nginx-ingress-controller
23 - --configmap=$(POD_NAMESPACE)/nginx-configuration
24 - --default-backend-service=app-space/default-http-backend
25 env:
26 - name: POD_NAME
27 valueFrom:
28 fieldRef:
29 fieldPath: metadata.name
30 - name: POD_NAMESPACE
31 valueFrom:
32 fieldRef:
33 fieldPath: metadata.namespace
34 ports:
35 - name: http
36 containerPort: 80
37 - name: https
38 containerPort: 443
You may also need to create a ConfigMap with things like err-log-path, keep-alive, and SSL-protocols and pass that in.
1#example ingress config map
2kind: ConfigMap
3apiVersion: v1
4metadata:
5 name: nginx-configuration
6...
Then create a service to expose the service to the external world:
1# nginx-ingress service exposing ports and linking service to deployment
2apiVersion: v1
3kind: Service
4metadata:
5 name: nginx-ingress
6spec:
7 type: NodePort
8 ports:
9 - port: 80
10 targetPort: 80
11 protocol: TCP
12 name: http
13
14 - port: 443
15 targetPort: 443
16 protocol: TCP
17 name: https
18 selector:
19 name: nginx-ingress
If you want to monitor the ingress, you will need to create a service account with the correct roles, clusterRoles, and roleBindings:
1# ingress service service account
2apiVersion: v1
3kind: ServiceAccount
4metadata:
5 name: nginx-ingress-serviceaccount
6...
Create an ingress resource to route traffic:
1#ingress-wear.yaml
2apiVersion: extensions/v1beta1
3kind: Ingress
4metadata:
5 name: ingress-wear
6spec:
7 # backend - defines where the traffic will be routed to
8 backend:
9 # use service if you only have one service to worry about
10 serviceName: wear-service
11 servicePort: 80
View ingress resource:
1kubectl get ingress
Get ingress resource details:
1kubectl describe ingress <ingress-name>
1# ingress-wear-watch.yaml with path rules
2# website.com/wear & website.com/watch
3apiVersion: networking.k8s.io/v1
4kind: Ingress
5metadata:
6 name: ingress-wear-watch
7 namespace: app-space
8 annotations:
9 nginx.ingress.kubernetes.io/rewrite-target: /
10 nginx.ingress.kubernetes.io/ssl-redirect: "false"
11spec:
12# backend - defines where the traffic will be routed to
13 rules:
14 - http:
15 paths:
16 - path: /wear
17 pathType: Prefix
18 backend:
19 service:
20 name: wear-service
21 port:
22 number: 8080
23 - path: /watch
24 pathType: Prefix
25 backend:
26 service:
27 name: video-service
28 port:
29 number: 8080
The default backend is where a user will be redirected if they specify a URL that doesn’t match any rules (so you must remember to deploy such a service).
Create ingress rules with multiple domain names (subdomains):
1# ingress-wear-watch.yaml with domain rules
2# wear.website.com & watch.website.com
3apiVersion: extensions/v1beta1
4kind: Ingress
5metadata:
6 name: ingress-wear
7spec:
8 # backend: (I'm not sure if this is required)
9 rules:
10 - host: wear.website.com
11 http:
12 paths:
13 - backend:
14 serviceName: wear-service
15 servicePort: 80
16 - host: watch.website.com
17 http:
18 paths:
19 - backend:
20 serviceName: watch-service
21 servicePort: 80
Changes have been made in previous and current versions in Ingress. Like in apiVersion, serviceName and servicePort etc.
In Kubernetes version 1.20+, we can create an Ingress resource in the imperative way like this:-
1kubectl create ingress <ingress-name> --rule="host/path=service:port"
1kubectl create ingress ingress-test --rule="shop.my-online-store.com/product*=shop-service:80"
Different ingress controllers have different options that can be used to customize the way it works. NGINX Ingress controller has many options that can be seen here.
The Rewrite target option:
- Our
watchapp displays the video streaming webpage athttp://<watch-service>:<port>/ - Our
wearapp displays the apparel webpage athttp://<wear-service>:<port>/
We must configure Ingress to achieve the below. When a user visits the URL on the left, his/her request should be forwarded internally to the URL on the right. Note that the /watch and /wear URL paths are what we configure on the ingress controller so we can forward users to the appropriate application in the backend. The applications don’t have this URL/Path configured on them:
```bash
http://<ingress-service>:<ingress-port>/watch –> http://<watch-service>:<port>/
http://<ingress-service>:<ingress-port>/wear –> http://<wear-service>:<port>/
```
Without the rewrite-target option, this is what would happen:
```bash
http://<ingress-service>:<ingress-port>/watch –> http://<watch-service>:<port>/watch
http://<ingress-service>:<ingress-port>/wear –> http://<wear-service>:<port>/wear
```
Notice watch and wear at the end of the target URLs. The target applications are not configured with /watch or /wear paths. They are different applications built specifically for their purpose, so they don’t expect /watch or /wear in the URLs. And as such, the requests would fail and throw a 404 not found error.
To fix that, we want to “ReWrite” the URL when the request is passed on to the watch or wear applications. We don’t want to pass in the same path that the user typed in. So we specify the rewrite-target option. This rewrites the URL by replacing whatever is under rules->http->paths->path which happens to be /pay in this case with the value in rewrite-target. This works just like a search and replace function.
For example: replace(path, rewrite-target).
In our case: replace("/path","/").
1apiVersion: extensions/v1beta1
2kind: Ingress
3metadata:
4 name: test-ingress
5 namespace: critical-space
6 annotations:
7 nginx.ingress.kubernetes.io/rewrite-target: /
8spec:
9 rules:
10 - http:
11 paths:
12 - path: /pay
13 backend:
14 serviceName: pay-service
15 servicePort: 8282
In another example given here, this could also be: replace("/something(/|$)(.*)", "/$2").
1apiVersion: extensions/v1beta1
2kind: Ingress
3metadata:
4 annotations:
5 nginx.ingress.kubernetes.io/rewrite-target: /$2
6 name: rewrite
7 namespace: default
8spec:
9 rules:
10 - host: rewrite.bar.com
11 http:
12 paths:
13 - backend:
14 serviceName: http-svc
15 servicePort: 80
16 path: /something(/|$)(.*)
Design & Install a Kubernetes Cluster
You can have master nodes all in active state for HA, but it’s best to have a loadbalancer to split traffic between them. Schedulers and controller managers should be in active/passive state.
To set a master node leader:
1kube-controller-manager --leader-elect true [other options]
- Set active/standby duration flag -
--leader-elect-lease-duration 15s - Set renewal time flag -
--leader-elect-renew-deadline 10s - Set how often master nodes try to become leader flag -
--leader-elect-retry-period 2s
This is the same for the scheduler too.
Stacked controlplane topology is when ETCD is on the same master node as the API server, Controller Manager, and Scheduler (easier to setup/manage but less redundant).
External ETCD topology is when the ETCD processes are on their own external server but is harder to setup and needs more servers.
/etc/systemd/system/kube-apiserver.service specifies where the ETCD service is:
1--etcd-servers=https://10.10.0.10:2379,https://10.10.0.11:2379
In a HA topology, ETCD ensures that the same data is found on all of its servers.
Internally the nodes elect a leader among them, and only one node actually writes data and then distributed the copied data to the followers. A write is only considered complete if the leader gets consent from the other members of the cluster and is written on a majority of the nodes in the cluster (quorum = N/2 + 1).
If you have two instances, it’s basically the same as having one instance due to quorum because if you lose one instance, you would lose both. There are better chances of your nodes staying alive due to network segmentation if you have an odd number of nodes.
ETCD implements distributed consensus using the RAFT protocol. They pick a random leader based on its random request, but if the follower nodes don’t hear from it for a while, then they themselves initiate the leader election process.
Install ETCD on a node:
1wget -q --https-only \
2"https://github.com/coreos/etcd/releases/download/v3.4.0/etcd-v3.4.0-linux-amd64.tar.gz"
3
4tar -xfv etcd-v3.4.0-linux-amd64.tar.gz
5
6mv etcd-v3.4.0-linux-amd64/etcd* /usr/local/bin/
7
8mkdir -p /etc/etcd /var/lib/etcd
9
10cp ca.pem kubernetes-key.pem kubernetes.pem /etc/etcd/
Configure the ETCD service:
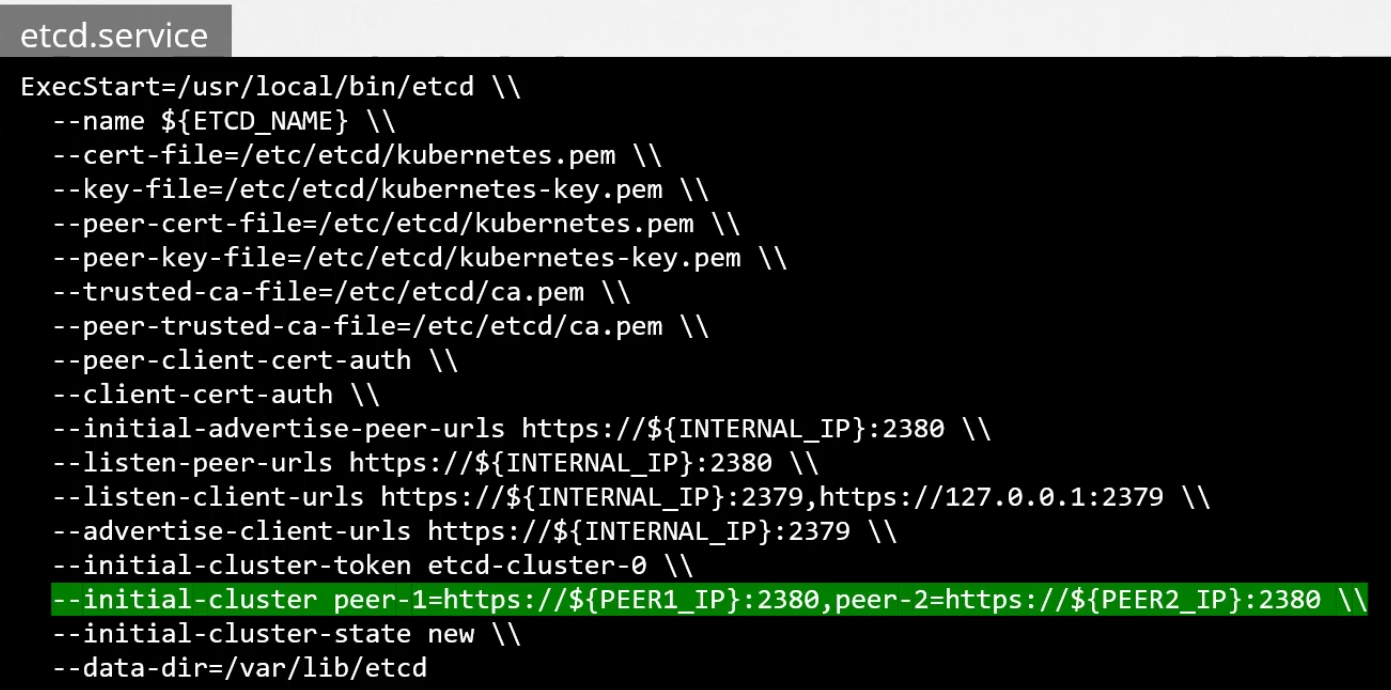
Use the ETCDCTL utility to store and retrieve data:
1export ETCDCTL_API=3
2
3extdctl put name john
4etcdctl get name
5
6etcdctl get / --prefix --keys-only
The minimum number of master nodes for HA is 3!
Troubleshooting
Application Failure
- Draw how your app is configured.
- Check using curl.
- Check the service to see if it has been discovered/exposed.
- Compare selectors.
- Check pod status & restarts.
- Use
kubectl describe/logs. - You might not be able to see the pod’s logs so use the
-fand--previousto see the logs of the previous pod.
- Use
- Check DB service.
- Check pod.
Controlplane Failure
-
Check the status of the nodes.
-
Check the status of the pods.
-
Check
kube-systempods. -
Check controlplane services:
1service kube-apiserver status 2service kube-controller-manager status 3service kube-scheduler status -
Check worker node services:
1service kubelet status 2service kube-proxy status -
Check service logs:
1kubectl logs kube-apiserver-master -n kube-system 2sudo journalctl -u kube-apiserver
Worker Node Failure
-
Check the status of the nodes.
-
Check the details of the nodes (describe).
- Check status and last heartbeat time.
-
If the node crashes, check for CPU and disk space issues
(top/df -h). -
Check the status of the kubelet:
1service kubelet statusCheck kubelet logs:
1sudo journalctl -u kubeletCheck kubelet certs:
1openssl x509 -in /var/lib/kubelet/<worker>.crt -text
Networking
Kubernetes uses CNI plugins to setup the network. The kubelet is responsible for executing plugins as we mention the following parameters in kubelet configuration:
–-cni-bin-dir: Kubelet probes this directory for plugins on startup–-network-plugin: The network plugin to use fromcni-bin-dir. It must match the name reported by a plugin probed from the plugin directory
In the CKA and CKAD exams, you won’t be asked to install the CNI plugin. But if asked, you will receive the exact URL to install it. If not, you can install Weavenet from the documentation.
DNS
Kubernetes resources for coreDNS are:
- A service account named
coredns, - Cluster-roles named
corednsandkube-dns - Clusterrolebindings named
corednsandkube-dns, - A deployment named
coredns, - A configmap named
corednsand a - Service named
kube-dns.
While analyzing the coreDNS deployment, you can see that the Corefile plugin consists of an important configuration, which is defined as a configmap.
Port 53 is used for DNS resolution.
1 kubernetes cluster.local in-addr.arpa ip6.arpa {
2 pods insecure
3 fallthrough in-addr.arpa ip6.arpa
4 ttl 30
5 }
This is the backend to Kubernetes for cluster.local and reverse domains.
1proxy . /etc/resolv.conf
Forward out-of-cluster domains directly to the right authoritative DNS server.
- If you find CoreDNS pods in a pending state, first check network plugin is installed.
- CoreDNS pods have CrashLoopBackOff or Error state.
- If you have nodes that are running SELinux with an older version of Docker, you might experience a scenario where the coreDNS pods are not starting. To solve that, you can try one of the following options:
- Upgrade to a newer version of Docker.
- Disable SELinux.
- Modify the coreDNS deployment to set allowPrivilegeEscalation to true:
1kubectl -n kube-system get deployment coredns -o yaml | \
2 sed 's/allowPrivilegeEscalation: false/allowPrivilegeEscalation: true/g' | \
3 kubectl apply -f -
- Another cause for CoreDNS to have CrashLoopBackOff is when a CoreDNS Pod deployed in Kubernetes detects a loop. There are many ways to work around this issue; some are listed here:
- Add the following to your kubelet config yaml:
resolvConf: <path-to-your-real-resolv-conf-file>This flag tells kubelet to pass an alternate resolv.conf to Pods. For systems using systemd-resolved,/run/systemd/resolve/resolv.confis typically the location of the “real” resolv.conf, although this can be different depending on your distribution. - Disable the local DNS cache on host nodes, and restore
/etc/resolv.confto the original. - A quick fix is to edit your Corefile, replacing forward_._
/etc/resolv.confwith the IP address of your upstream DNS, for example, forward**.**8.8.8.8. But this only fixes the issue for CoreDNS; kubelet will continue to forward the invalid resolv.conf to all default dnsPolicy Pods, leaving them unable to resolve DNS.
- Add the following to your kubelet config yaml:
- If CoreDNS pods and the kube-dns service is working fine, check the kube-dns service has valid endpoints.
1kubectl -n kube-system get ep kube-dns
- If there are no endpoints for the service, inspect the service and make sure it uses the correct selectors and ports
Kube-Proxy
kube-proxy is a network proxy that runs on each node in the cluster. kube-proxy maintains network rules on nodes. These network rules allow network communication to the Pods from network sessions inside or outside of the cluster. kubeproxy is responsible for watching services and endpoints associated with each service. When the client connects to the service using the virtual IP, the kubeproxy sends traffic to actual pods.
In a cluster configured with kubeadm, you can find kube-proxy as a daemonset.
If you run a kubectl describe ds kube-proxy -n kube-system, you can see that the kube-proxy binary runs with the following command inside the kube-proxy container.
1...
2 /usr/local/bin/kube-proxy
3 --config=/var/lib/kube-proxy/config.conf
4 --hostname-override=$(NODE_NAME)
So it fetches the configuration from a configuration file, i.e., /var/lib/kube-proxy/config.conf, and we can override the hostname with the node name at which the pod is running.
In the config file we define the clusterCIDR****, kubeproxy mode****, ipvs****, iptables****, bindaddress****, kube-config****, etc.
- Check
kube-proxypod in thekube-systemnamespace is running. - Check
kube-proxylogs. - Check
configmapis correctly defined and that the config file for runningkube-proxybinary is correct. kube-configis defined in theconfig map.- check
kube-proxyis running inside the container
1# netstat -plan | grep kube-proxy
2tcp 0 0 0.0.0.0:30081 0.0.0.0:* LISTEN 1/kube-proxy
3tcp 0 0 127.0.0.1:10249 0.0.0.0:* LISTEN 1/kube-proxy
4tcp 0 0 172.17.0.12:33706 172.17.0.12:6443 ESTABLISHED 1/kube-proxy
5tcp6 0 0 :::10256 :::* LISTEN 1/kube-proxy
References:
Debug Service issues:
https://kubernetes.io/docs/tasks/debug-application-cluster/debug-service/
DNS Troubleshooting:
https://kubernetes.io/docs/tasks/administer-cluster/dns-debugging-resolution/
JSON Path in Kubernetes
JSON path is good for querying lots of nodes/pods
- Use the
-o jsonto see the order of kubectl output
1kubectl get pods -o=jsonpath='{.items[0].spec.containers[0].image}'
2
3# String multiple queries together
4kubectl get nodes -o=jsonpath='{.items[*].metadata.name}{"\n"}{.items[*].status.capacity.cpu}'
5
6# To use loops in JSON path:
7FOR EACH NODE
8 PRINT NODE NAME \t PRINT CPU COUNT \n
9END FOR
10
11'{range .items[*]}
12 {.metadata.name}{"\t"}{.status.capacity.cpu}{"\n"}
13{end}'
Make output into columns (No spaces when adding comma):
1kubectl get nodes -o=custom-columns=NODE:.metadata.name,CPU:.status.capacity.cpu
2
3# Output:
4# NODE CPU
5# master 4
6# node01 4